In Kubernetes node rotation (node cycling) concept we have two main approaches.
- Add new node → remove old node.
- Remove old node → Add new node.
The 1st strategy is more obvious, since applications should have enough room to function. If we remove a node before adding a new node, the cluster will be in a Low CPU/RAM state for a short period of time. This will lead to a malfunction or unintended behaviors of the application.
First let’s walk around a little bit to see what are the variations of Kubernetes engine.
- Azure Kubernetes Service (AKS)
- Linode Kubernetes Engine
- Google Kubernetes Engine (GKE)
- Amazon Elastic Kubernetes Service (EKS)
- k3s (By Rancher)
- Minikube (lightweight Kubernetes implementation for development and testing purposes)
- Vanilla Kubernetes Engine (kubeadm)
This study will be going around kubeadm. The vanilla Kubernetes engine. When it comes to customizability, kubeadm plays a major role. Because it’s the vanilla way of how Kubernetes works.
Application => Most of the time I refer “Application” here to imply “The micro service application installed within Kubernetes engine“
Benefits
Infrastructure migration or maintenance becomes easier
Assume a scenario where you need to migrate the nodes (End of the day they will become VMs or other bare metal hardware). There may be server maintenance, mother board replacement etc..
In this case you have to bring the Kubernetes operating cluster out from the existing bare-metal hardware to another one. We can apply node rotation technique here. Provision each new node in the new infrastructure and join to the cluster. Eventually nodes in the old infrastructure will be removed leaving the system within new infrastructure.
Assume “Node C” was also in “Old Infrastructure”.
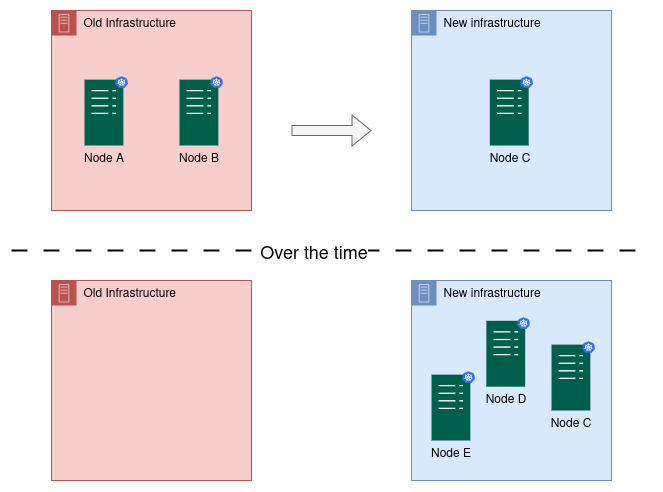
Here node A and B vanished. But entire application within the Kubernetes engine is pushed to new Kubernetes nodes.
This approach enables seamless infrastructure migration without exposing any disruptions to end users.
Pods get evenly distributed
Some nodes are heavily loaded with application pods while other nodes only have system-level or default management pods like kube-proxy, kubelet, coredns.
We call this scenario in simple English “uneven pod distribution” or “Pod Skew / Pod Imbalance” in technical terms.
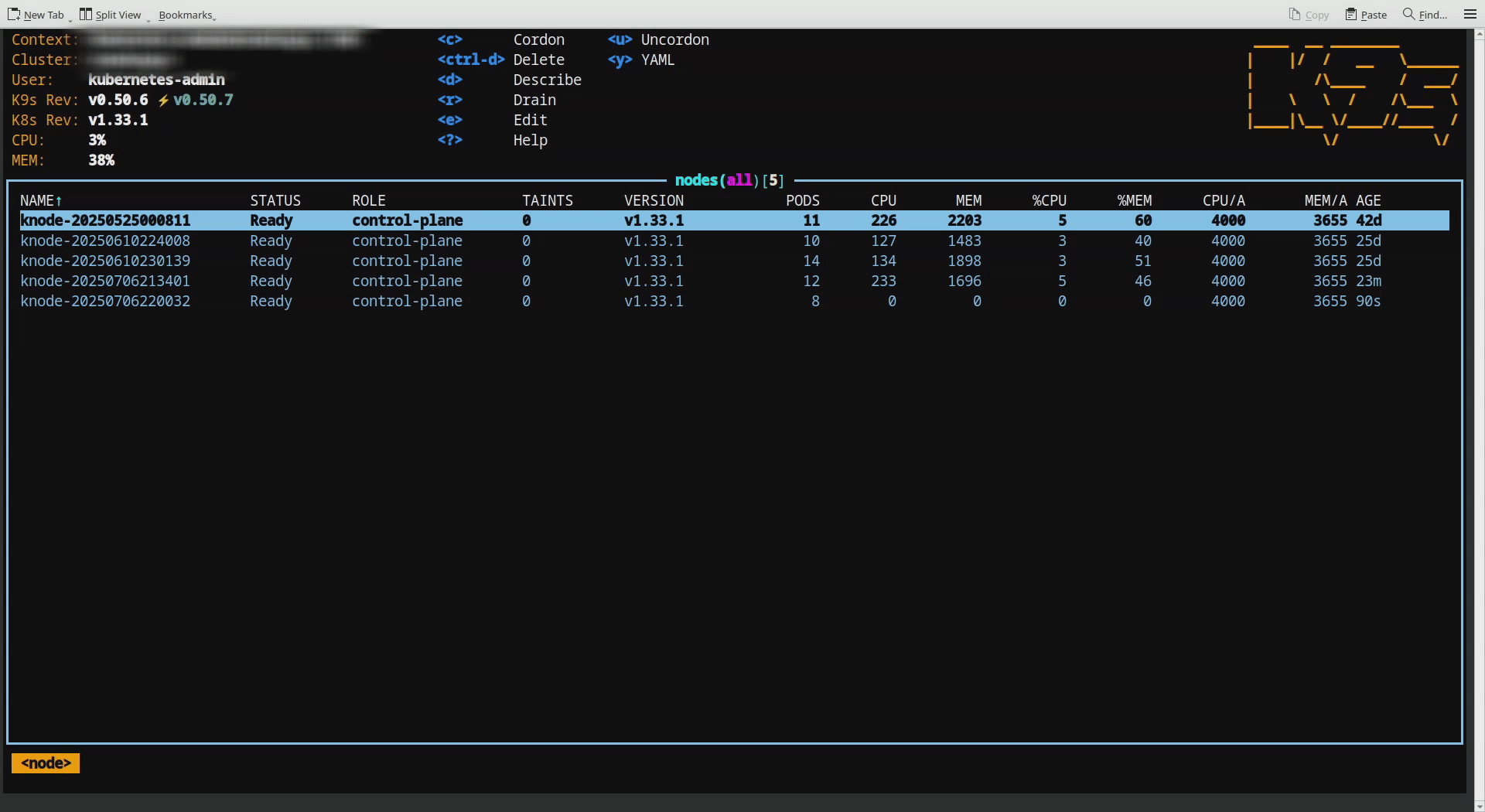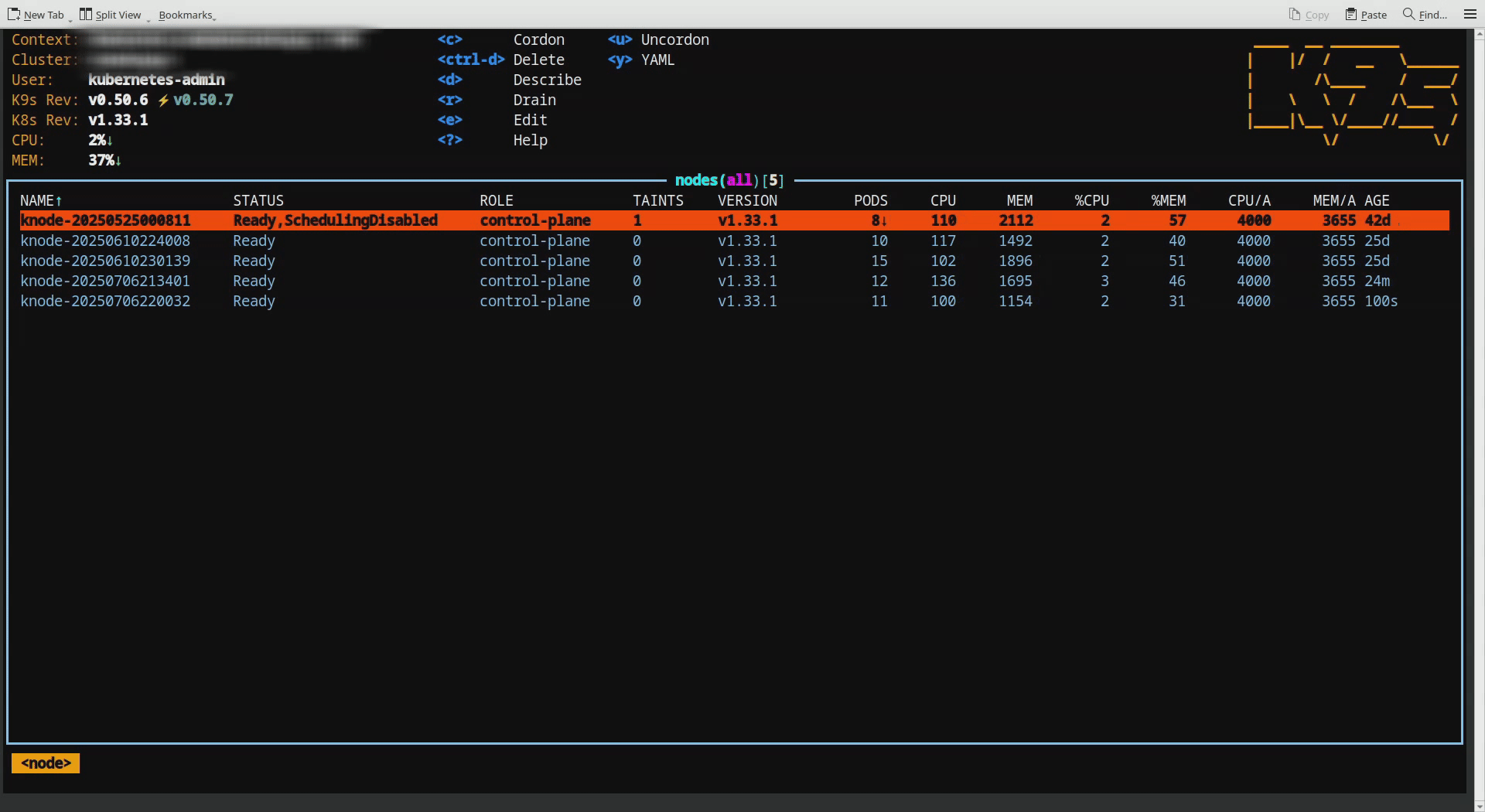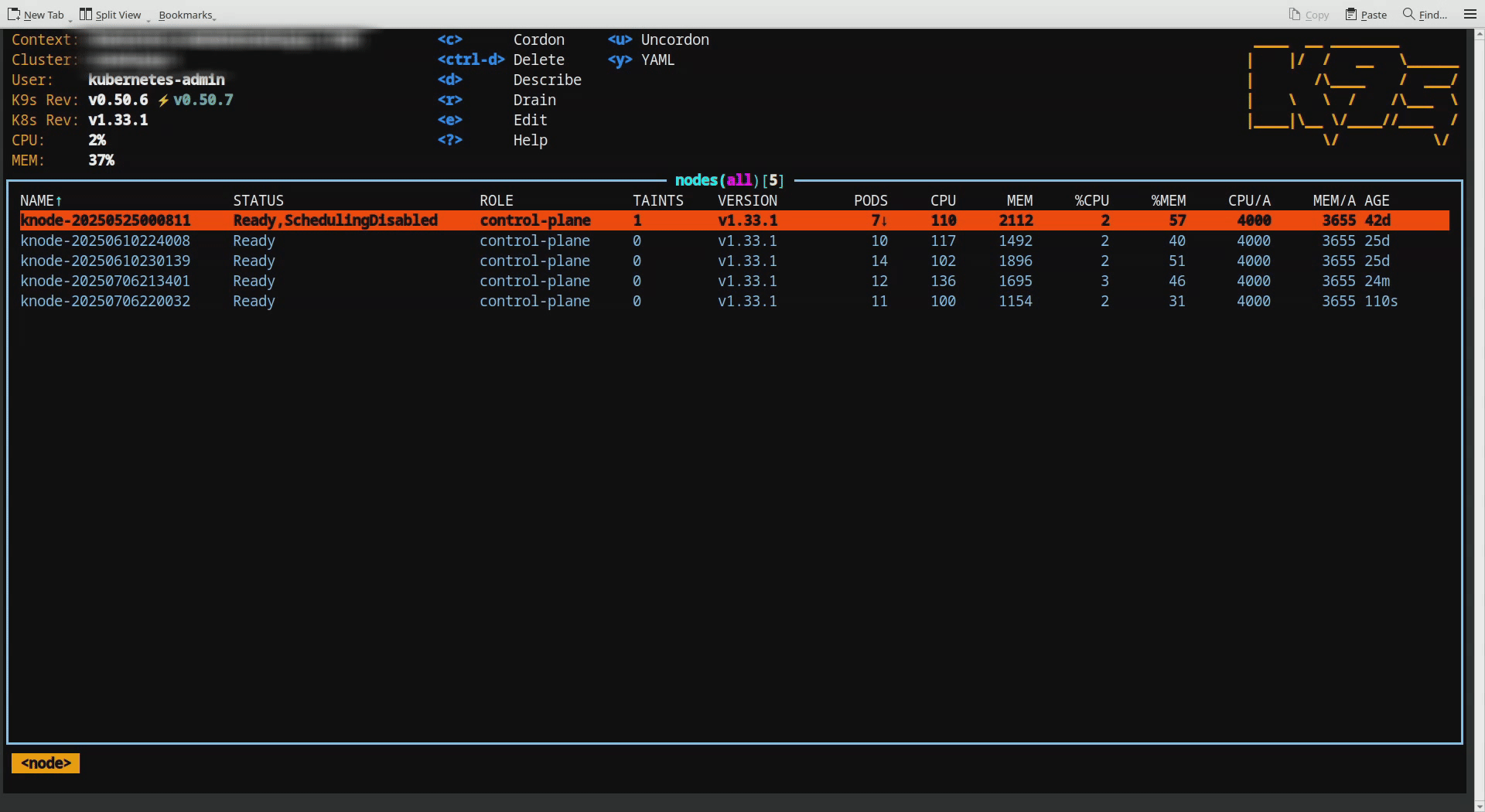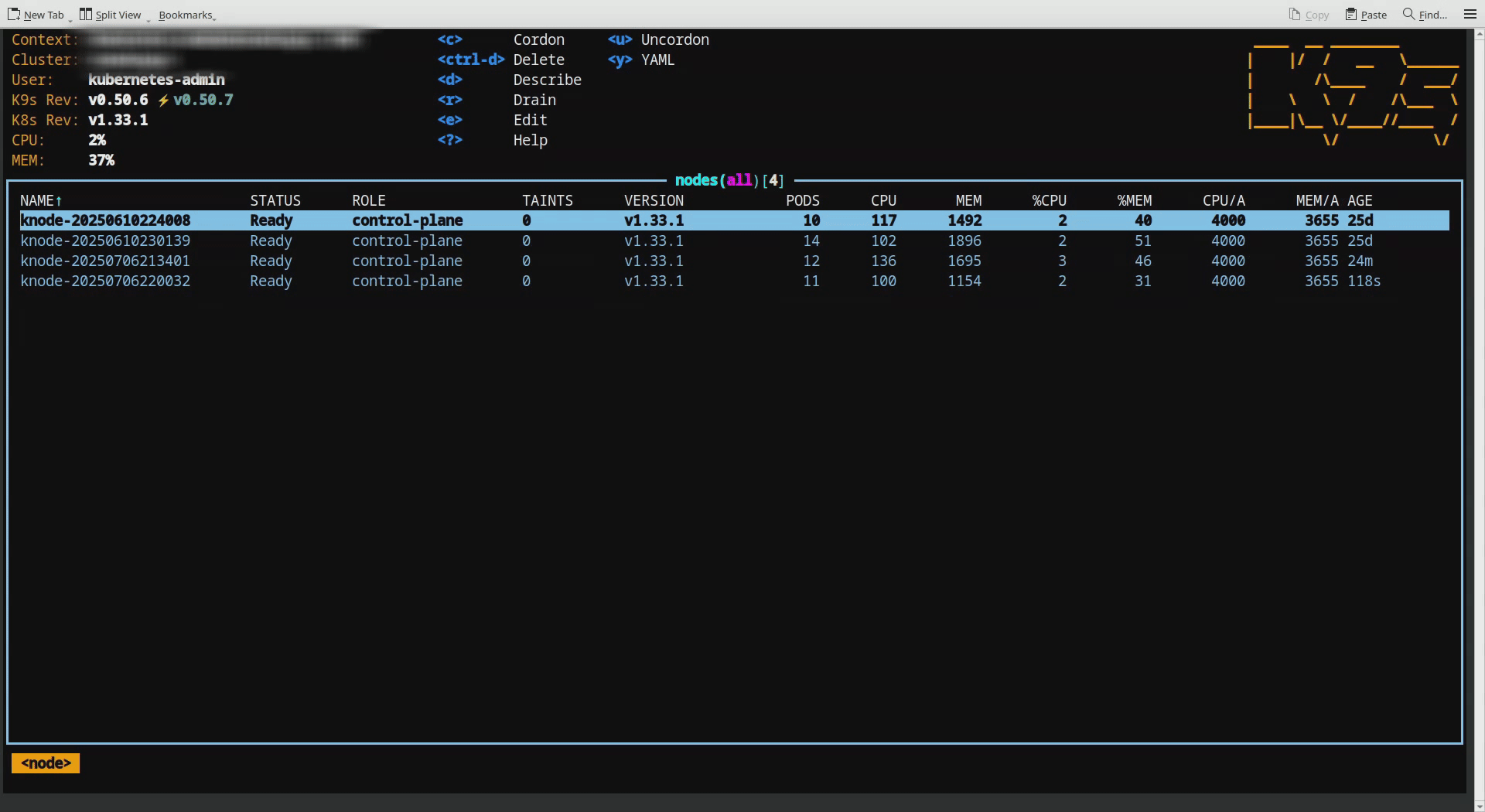
In the “Practical Approach” section down below, first illustration shows new node addition to the cluster. It only had 8 pods, as soon as added to the cluster. These are only management level pods.
In the second illustration, when another node got detached from the cluster, pods that was on draining node are immediately redistributed across the remaining nodes. This results in a balanced distribution of pods, maintaining an average load across the cluster.
Refreshness comes as a benefit
There are plenty of programming languages out there. But the bitter truth is “resource exhaustion” 😄. No matter what programming language used in the application, human errors everywhere.
Assume a scenario that one of the application running within a pod consume memory gradually and at the middle it get OOM killed causing application malfunctions for a short period of time. If carefully planned node cycling established, the entire application will be in a refreshed state. No over the time OOM kills.
You may be using a third party application as a pod running within your cluster. Think of the development of that particular application. It may have memory leaks over the time. So you are out of control fixing that. But instead what you can do is let it cleanly refresh by Kubernetes node cycling.
Security comes as a benefit
Assume having a 3 node Kubernetes cluster. OS distribution provider makes their critical security fix available on package management system. No option, entire cluster should have new version of OS with security fix. But without interruption to the application.
With node cycling. Add new node into the cluster with new OS upgrade and remove one old node at a time. After repeating this for all nodes, the cluster will have newest OS upgrade without interrupting to the Kubernetes functions and applications running on it.
Imagine a scenario an attacker has installed an OS level malware. Node cycling during regular intervals (6 hour, 12 hour, 24 hour) gives no room for a malware based hijack.
We all know that modern attackers can do things in few minutes 😄.
Application design strategies with Kubernetes Node rotation.
Make sure pods are defensive to node rotation. There are situations where your application availability is critical. So that end users can interact with the system without unintended behaviors.
First there is a guideline we have to keep following.
- Pod Disruption Budget (PDB)
This will ensure min N pods remain available before eviction. For example let’s say you have 4 replicas of an application and PDB allocated to that specific set of pods describes that at least 2 pods should be available. So when draining triggered, Kubernetes cluster will keep 2 pods alive except those who are on the draining nodes.
preStopHook (Pod Lifecycle Hook) + Termination Grace Period
When the node is about to be drained, the Kubernetes control plane initiates eviction for all pods on that node. For each pod, Kubernetes sends a termination signal (SIGTERM) to the container(s).
Before the SIGTERM is processed, if the pod has a defined preStop hook, Kubernetes executes the preStop hook first.
eg:-
apiVersion: apps/v1
kind: Deployment
metadata:
name: critical-app
spec:
replicas: 2
template:
metadata:
labels:
app: critical-app
spec:
terminationGracePeriodSeconds: 60
containers:
- name: app
image: critical-image
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "curl -X POST http://<some internal url>/termination-procedure && sleep 10"]
If developers program /termination-procedure API endpoint, cleanup operation can be handled programmatically.
Kubernetes waits up to the configured terminationGracePeriodSeconds and terminate the pod. During this phase pod can be developed for it’s own cleanup operations. This is a voluntary draining (No Node crash).
The other important thing is volume provisioning. Some of your applications might be using volumes via a volume provisionner. That part I’m not going to talk in detail here. But that also a must planning ahead for Kubernetes node rotation.
Practical approach
Tools:
- Hypervisor software for provisioning VMs (Kubernetes node)
- Configuration tool for installing
kubeadmand cluster joining. - Coordination mechanism (A program) from VM provisioning to Kubernetes cluster join.
Each node you see here is a 4GB kubeadm installed Linux based distribution.
A Kubernetes node get added to the existing cluster.

This shows node removal scenario.